Managementul incidentelor și problemelor - concepte și principii. Exemple de accidente și incidente aviatice
Cauza principală a unui incident de securitate a informațiilor este capacitatea potențială a unui atacator de a obține privilegii nerezonabile pentru a accesa bunul unei organizații. Evaluarea riscului unei astfel de oportunități și luarea deciziei corecte de protejare este sarcina principală a echipei de răspuns.
Fiecare risc trebuie să fie prioritizat și tratat în conformitate cu politica de evaluare a riscurilor a organizației. Evaluarea riscurilor este văzută ca un proces continuu, al cărui scop este atingerea unui nivel acceptabil de protecție, cu alte cuvinte, trebuie puse în aplicare suficiente măsuri pentru a proteja activul împotriva utilizării nerezonabile sau neautorizate. Evaluarea riscurilor contribuie la clasificarea activelor. În marea majoritate a cazurilor, activele care sunt critice din punct de vedere al riscului sunt, de asemenea, critice pentru afacerea organizației.
Specialiștii echipei de răspuns analizează amenințările și ajută la menținerea la zi a modelului de intrus adoptat de serviciul de securitate a informațiilor al organizației.
Pentru ca echipa de răspuns să funcționeze eficient, organizația trebuie să aibă proceduri care să descrie procesele de funcționare ale unităților. O atenție deosebită trebuie acordată completării bazei de documente a serviciului de securitate a informațiilor.
Detectarea și analiza incidentelor de securitate a informațiilor
Incidentele de securitate a informațiilor pot avea surse diferite de origine. În mod ideal, o organizație ar trebui să fie pregătită pentru orice manifestare de activitate rău intenționată. În practică, acest lucru nu este fezabil.
Funcția de răspuns trebuie să clasifice și să descrie fiecare incident care are loc în organizație, precum și să clasifice și să descrie posibilele incidente care au fost presupuse pe baza analizei de risc.
Pentru a extinde tezaurul despre posibilele amenințări și posibilele incidente asociate cu acestea, o bună practică este utilizarea surselor deschise actualizate constant pe Internet.
Semne ale unui incident de securitate a informațiilor
Presupunerea că un incident de securitate a informațiilor a avut loc într-o organizație ar trebui să se bazeze pe trei factori principali:
- Mesajele de incident de securitate a informațiilor sunt primite simultan din mai multe surse (utilizatori, IDS, fișiere jurnal)
- Semnal IDS eveniment repetat multiplu
- Analiza fișierelor jurnal ale sistemului automat oferă o bază pentru administratorii de sistem pentru a concluziona că poate avea loc un eveniment incident.
În general, semnele unui incident se împart în două categorii principale, raportează că un incident are loc în prezent și raportează că un incident poate avea loc în viitorul apropiat. Următoarele sunt câteva semne ale unui eveniment care are loc:
- IDS detectează depășirea tamponului
- notificare program antivirus
- Blocarea interfeței WEB
- Utilizatorii raportează viteze extrem de mici atunci când încearcă să acceseze Internetul
- administratorul de sistem detectează prezența fișierelor cu nume imposibil de citit
- Utilizatorii raportează multe mesaje duplicate în căsuțele lor de e-mail
- gazda scrie în jurnalul de audit despre modificarea configurației
- aplicația înregistrează mai multe încercări de autorizare nereușite în fișierul jurnal
- administratorul de rețea detectează o creștere bruscă a traficului de rețea etc.
Exemple de evenimente care pot servi ca surse de securitate a informațiilor includ:
- fișierele jurnal ale serverului înregistrează scanările de porturi
- anunț în mass-media despre apariția unui nou tip de exploatare
- o declarație deschisă a criminalilor informatici care declară război organizației dvs. etc.
Analiza incidentelor de securitate a informațiilor
Incidentul nu este un fapt împlinit evident; dimpotrivă, atacatorii încearcă să facă totul pentru a nu lăsa urme ale activităților lor în sistem. Semnele unui incident includ o modificare minoră în fișierul de configurare a serverului sau, la prima vedere, o plângere standard a utilizatorului de e-mail. Luarea unei decizii cu privire la apariția unui eveniment incident depinde în mare măsură de competența experților echipei de răspuns. Este necesar să se facă distincția între o eroare accidentală a operatorului și un impact rău intenționat, direcționat, asupra unui sistem informațional. Faptul că un incident de securitate a informațiilor este tratat „întuneric” este, de asemenea, un incident de securitate a informațiilor, deoarece îi distrage atenția experților echipei de răspuns de la problemele stringente. Conducerea organizației ar trebui să acorde atenție acestei circumstanțe și să ofere experților echipei de răspuns o anumită libertate de acțiune.
Compilarea matricelor de diagnostic servește la vizualizarea rezultatelor analizei evenimentelor care au loc în sistemul informațional. Matricea este formată din rânduri de semne potențiale ale unui incident și coloane de tipuri de incidente. Intersecția oferă o evaluare a evenimentului pe scara de prioritate „înalt”, „mediu”, „scăzut”. Matricea de diagnosticare este menită să documenteze fluxul de concluzii logice ale experților în procesul de luare a deciziilor și, împreună cu alte documente, servește ca dovadă a investigației incidentului.
Documentarea unui incident de securitate a informațiilor
Documentarea evenimentelor unui incident de securitate a informațiilor este necesară pentru a colecta și, ulterior, consolidarea probelor investigației. Toate faptele și dovezile de influență rău intenționată trebuie să fie documentate. Se face o distincție între dovezile tehnologice și dovezile operaționale ale impactului. Dovezile tehnologice includ informații obținute din mijloacele tehnice de colectare și analiză a datelor (sniffer, IDS); dovezile operaționale includ date sau dovezi colectate în timpul unei anchete de personal, dovezi ale apelurilor către biroul de service, apeluri către call center.
O practică tipică este menținerea unui jurnal de investigare a incidentelor, care nu are un formular standard și este elaborat de echipa de răspuns. Pozițiile cheie ale unor astfel de reviste pot fi:
- stadiul actual al anchetei
- descrierea incidentului
- acțiunile efectuate de echipa de răspuns în timpul procesării incidentului
- lista actorilor de anchetă cu o descriere a funcțiilor acestora și a procentului de angajare în procedura de investigație
- lista de probe (cu indicarea obligatorie a surselor) colectate în timpul procesării incidentului
Pe măsură ce rolul IT într-o companie crește, la fel crește și nevoia de a asigura un nivel bun de servicii și de a asigura disponibilitatea maximă a serviciilor IT. Utilizatorul de afaceri ar trebui să poată găsi soluții la problemele sale dacă acestea apar cât mai repede posibil și lucrează în orice moment. Implementarea proceselor gestionarea incidentelor iar problemele vizează tocmai acest lucru. În acest articol descriem modul în care activitatea unui serviciu IT poate fi organizată în cadrul gestionarea incidentelor si probleme. Această descriere se bazează pe sugestiile ITIL și pe experiențele clienților noștri.
Limbajul incidentelor și problemelor
ITIL Service Support este un model recunoscut la nivel global. Se bazează pe cele mai bune practici și este folosit pentru a ghida organizațiile IT în dezvoltarea abordărilor pentru managementul serviciilor. Acest model este promițător. De asemenea, definește elemente suplimentare necesare pentru funcționarea cu succes a unei organizații IT ca afacere de servicii. Acesta oferă un vocabular tehnic pentru discuțiile de la biroul de asistență, definește concepte și evidențiază diferențele dintre diferite activități. De exemplu, activitățile necesare pentru a răspunde la întreruperile serviciului și pentru a le restabili sunt diferite de activitățile necesare pentru a găsi și elimina cauzele întreruperilor serviciului.
Incidente
Incident- orice eveniment care nu face parte din operațiunile standard ale serviciului și provoacă sau poate provoca o întrerupere a serviciului sau o scădere a calității serviciului.
Exemple de incidente sunt:
- Utilizatorul nu poate primi e-mail
- Instrumentul de monitorizare a rețelei indică faptul că canalul de comunicare va deveni în curând plin
- Utilizatorul simte că aplicația încetinește
Probleme
Problemă— există o cauză necunoscută pentru unul sau mai multe incidente.O problemă poate da naștere la mai multe incidente.
Erori
Bug cunoscut— există un incident sau o problemă pentru care a fost identificată cauza și a fost dezvoltată o soluție pentru a o ocoli sau a o elimina. Erorile pot fi identificate prin analiza reclamațiilor utilizatorilor sau analiza sistemelor.
Exemple de erori includ:
- Configurare incorectă a rețelei de calculatoare
- Instrumentul de monitorizare determină incorect starea canalului atunci când routerul este ocupat
Corelarea conceptelor gestionarea incidentelor iar problemele sunt prezentate în Figura 1. Incidentele, problemele și erorile cunoscute sunt legate într-un fel de ciclu de viață: incidentele sunt adesea indicatori ai problemelor ⇒ identificarea cauzei problemei identifică eroarea ⇒ erorile sunt apoi corectate sistematic.
- există o activitate de restabilire a serviciului normal cu întârzieri minime și impact asupra operațiunilor de afaceri, care este un serviciu de restaurare reactiv, concentrat pe termen scurt.
Include:
- Detectarea și înregistrarea incidentelor
- Clasificare și suport inițial
- Cercetare și diagnosticare
- Soluție și recuperare
- Închidere
- Proprietate, monitorizare, urmărire și comunicare
Managementul problemelor
Managementul problemelor — există activități pentru a minimiza impactul asupra afacerii al problemelor cauzate de erori în infrastructura IT, pentru a preveni reapariția incidentelor asociate cu astfel de erori. Managementul problemelor identifică cauzele problemelor și identifică soluții sau soluții.
Managementul problemelor include:
- Controlul problemelor
- Controlul erorilor
- Prevenirea problemelor
- Analiza principalelor probleme
Controlul problemelor
Scopul controlului problemei— găsiți cauza problemei urmând acești pași:
- Identificarea și înregistrarea problemelor
- Clasificarea problemelor și prioritizarea soluțiilor acestora
- Cercetarea și diagnosticarea cauzelor
Controlul erorilor
Controlul erorilor asigură că problemele sunt corectate prin:
- Identificarea și înregistrarea erorilor cunoscute
- Evaluarea remediilor și prioritizarea acestora
- Înregistrare pentru o soluție temporară în instrumentele de asistență
- Închiderea problemelor cunoscute prin implementarea remedierilor
- Monitorizați erorile cunoscute pentru a determina necesitatea restabilirii priorităților
Analiza problemei
Scopul analizei problemei este de a îmbunătăți procesele gestionarea incidentelorși managementul problemelor. Ce se realizează prin studierea calității rezultatelor activităților pentru eliminarea problemelor și incidentelor majore.
Roluri organizaționale și repartizarea responsabilităților
Cea mai comună structură a sistemului de suport este un model pe niveluri în care niveluri crescânde de capabilități tehnice sunt aplicate pentru a rezolva un incident sau o problemă. Rolurile și responsabilitățile reale utilizate într-o implementare a unui sistem de suport pe niveluri pot varia în funcție de personalul, istoricul și politicile unei anumite organizații. Cu toate acestea, următoarea descriere a unui sistem de suport pe niveluri este tipică pentru multe organizații.
Primul nivel de suport
Organizația (diviziunea) care reprezintă primul nivel de suport se referă de obicei la servicii operaționale. De regulă, se numește serviciu de expediere, Call Center, Service Desk.
Roluri. Deținătorul procesului
Primul nivel de suport asigură stabilirea și menținerea unui proces bine definit, executat consecvent, măsurat corespunzător și eficient. gestionarea incidentelor. Primiți și gestionați toate problemele legate de serviciul clienți. Primul nivel de asistență este punctul unic de contact pentru escaladarea problemelor legate de servicii și acționează ca avocatul utilizatorului final pentru a se asigura că problemele legate de serviciu sunt rezolvate în timp util.
Prima linie de sprijin
Organizația de suport de primul nivel face prima încercare de a rezolva problema de serviciu raportată de utilizatorul final.
Responsabilitati
- Este garantat că cardul de incident conține o descriere exactă și suficient de detaliată a problemei
- Alegerea corectă a importanței/priorității incidentului este garantată
- Sunt determinate natura problemei, contactele utilizatorilor, impactul asupra afacerii și timpul estimat de rezolvare
Proprietatea fiecărui incident.În calitate de avocat al utilizatorului final, primul nivel de asistență asigură că fiecare incident este rezolvat cu succes. Acest lucru asigură rezolvarea în timp util a problemelor prin:
- Elaborarea și gestionarea unui plan de acțiune pentru rezolvarea problemei
- Inițierea sarcinilor specifice pentru personal și parteneri de afaceri
- Creșteți incidentul dacă este necesar atunci când obiectivul nu este atins la timp
- Asigurarea comunicarii interne in conformitate cu obiectivele serviciului
- Protejarea intereselor partenerilor de afaceri implicați
Primul nivel de asistență utilizează o bază de date de gestionare a problemelor pentru a potrivi incidentele cu erorile cunoscute și pentru a aplica incidentelor soluții descoperite anterior. Scopul este rezolvarea a 80% din incidente. Incidentele rămase sunt transferate (escalate) la al doilea nivel.
Îmbunătățirea continuă a procesului de management al incidentelor.În calitate de proprietar al unui anumit proces, primul nivel de asistență asigură că procesul este îmbunătățit atunci când este necesar prin:
- Evaluează eficacitatea procesului și a mecanismelor de sprijin, cum ar fi rapoarte, tipuri de comunicare și formate de mesaje, proceduri de escaladare
- Elaborarea rapoartelor și procedurilor specifice departamentului
- Sprijiniți și îmbunătățiți listele de comunicare și escaladare
- Participarea la procesul de analiză a problemei
Înregistrarea exactă a incidentelor. Primul nivel de asistență asigură că informațiile despre incident sunt înregistrate în jurnalul de sistem. Pentru aceasta trebuie să existe:
Abilități și aptitudini
Abilitățile interpersonale sunt primordiale. Personalul de suport de nivel întâi este implicat în primul rând în stabilirea priorităților și gestionarea problemelor. La acest nivel de suport, se efectuează doar cercetări tehnice minore. Abilitatea de a aplica soluții „conservate”. Personalul de la primul nivel trebuie să fie capabil să recunoască simptomele, să folosească instrumente de căutare pentru a descoperi soluții dezvoltate anterior și să asiste utilizatorii finali în implementarea unor astfel de soluții.
Al doilea nivel de sprijin
Acest nivel se referă de obicei și la serviciile operaționale.
Roluri
- Investigarea incidentului. Al doilea nivel de suport investighează, diagnostichează și rezolvă majoritatea incidentelor care nu sunt rezolvate la primul nivel. Aceste incidente tind să indice noi probleme.
- Proprietarul procesului de management al problemelor. Al doilea nivel de asistență asigură existența unui proces de management al problemelor bine definit și eficient.
- Management proactiv a infrastructurii. Al doilea nivel de asistență utilizează instrumente și procese pentru a se asigura că problemele sunt identificate și rezolvate înainte de apariția incidentelor.
Responsabilitati
- Rezolvarea incidentelor referite de la primul nivel. Dacă primul nivel de asistență este de așteptat să rezolve 80% dintre incidente, atunci cel de-al doilea nivel de asistență este de așteptat să rezolve 75% dintre incidentele la care se referă primul nivel, adică 15% din numărul de incidente raportate. Incidentele rămase sunt transferate la al treilea nivel.
- Determinarea cauzelor problemelor. Al doilea nivel de asistență identifică cauzele problemelor și sugerează soluții sau soluții. Ei angajează și gestionează alte resurse după cum este necesar pentru a determina cauzele. Rezolvarea problemelor este escaladată la al treilea nivel atunci când cauza este o problemă de arhitectură sau tehnică care depășește nivelul lor de calificare.
- Asigurați-vă că remediile și problemele sunt rezolvate. Al doilea nivel de suport asigură inițierea proiectelor în cadrul organizațiilor de dezvoltare pentru a implementa planuri de rezolvare a problemelor cunoscute. Ei se asigură că soluțiile găsite sunt documentate, comunicate personalului de prim nivel și implementate în instrumente.
- Monitorizarea constantă a infrastructurii. Al doilea nivel de asistență încearcă să identifice problemele înainte ca incidentele să apară prin monitorizarea componentelor infrastructurii și luând măsuri corective atunci când sunt detectate defecte sau tendințe eronate.
- Analiza proactivă a tendințelor incidentelor. Incidentele care au avut loc deja sunt examinate pentru a determina dacă indică probleme care trebuie corectate pentru a preveni ca acestea să provoace alte incidente. Acele incidente care sunt închise și nu sunt mapate la probleme cunoscute sunt examinate pentru probleme potențiale.
- Îmbunătățirea continuă a procesului de management al problemelor.În calitate de proprietar al procesului de management al problemelor, al doilea nivel de suport asigură că procesul și capacitățile existente sunt adecvate și le îmbunătățește atunci când este necesar. Ei desfășoară sesiuni de analiză a problemelor pentru a identifica lecțiile învățate și pentru a se asigura că controalele proceselor, cum ar fi întâlnirile și rapoartele, sunt adecvate.
Abilități și aptitudini
- Competent tehnic cu abilități rezonabile de comunicare. Personalul de asistență de nivel al doilea trebuie să aibă o serie de abilități tehnice în toate tehnologiile acceptate, inclusiv rețele, servere și aplicații. Un deficit comun în organizațiile de nivel al doilea este cunoașterea sistemelor de operare și a aplicațiilor. Nu ar trebui să existe un decalaj semnificativ între organizațiile de nivel al doilea și al treilea. Unii angajați de nivelul doi trebuie să fie la fel de calificați ca și angajații de nivelul trei.
- Cunoștințe despre rețele, servere și aplicații. Organizațiile de nivel 2 trebuie să fie capabile să rezolve incidentele și problemele din întreaga gamă de tehnologii utilizate în cadrul companiei.
Al treilea nivel de sprijin
Acest nivel de asistență se încadrează de obicei în echipa de dezvoltare a aplicațiilor și a infrastructurii de rețea.
Roluri
- planificarea și proiectarea infrastructurii IT. De obicei, echipa de suport de nivel al treilea joacă un rol mic în gestionarea incidentelorși managementul problemelor, deoarece astfel de organizații sunt preocupate în primul rând de planificarea și proiectarea infrastructurii IT. În această calitate, scopul lor este să implementeze o infrastructură fără defecte, care să nu fie sursa de probleme și incidente.
- Ultima frontieră în escaladare. Dacă incidentul sau problema depășește capacitățile echipei de asistență de nivel al doilea, atunci echipa de asistență de nivel al treilea își asumă responsabilitatea pentru găsirea unei soluții.
Responsabilitati
- Rezolvarea incidentelor referite de la nivelul doi. Deoarece majoritatea incidentelor sunt cauzate de erori cunoscute, foarte puține incidente (5%) trec de la al doilea la al treilea nivel. Al treilea nivel este responsabil pentru rezolvarea tuturor incidentelor care vin la ei.
- Participați la activități de management al problemelor. Al treilea nivel de asistență este implicat în găsirea cauzelor, soluții alternative și eliminarea erorilor.
- Implementarea măsurilor de eliminare a erorilor din infrastructură. Al treilea nivel are un rol semnificativ în planificarea, proiectarea și implementarea proiectelor pentru a aborda deficiențele infrastructurii. Implementarea acestor proiecte trebuie să fie coordonată cu lucrări regulate de dezvoltare a infrastructurii pentru a atinge echilibrul potrivit.
Abilități și aptitudini
- Experți în domeniile lor respective. Echipele de nivelul 3 ar trebui să fie experții care planifică și proiectează infrastructura IT.
Procese
Există trei procese principale asociate cu gestionarea incidentelor si managementul problemelor:
- proces de management al incidentelor
- procesul de control al problemei
- procesul de control al erorilor
Aceste procese de bază sunt prezente în aproape toate organizațiile avansate, deși pot avea alte nume.
Procesul de management al incidentelor
Acest proces este axat pe restabilirea serviciului întrerupt cât mai rapid posibil. Tabelul 1 prezintă principalii parametri ai acestui proces, iar Figura 1 prezintă o diagramă a funcționării acestuia.
|
Parametrul procesului |
Descriere |
|---|---|
|
Scop |
|
|
Proprietar |
|
|
|
|
|
|
Parametri numerici tipici |
|
Figura 1. Modelul procesului
Procesul de control al problemelor se concentrează pe prioritizarea, alocarea și monitorizarea eforturilor pentru a determina cauzele problemelor și modul de rezolvare temporară sau permanentă a acestora. Acest proces poate fi asemănat cu managementul portofoliului de proiecte, unde fiecare problemă este un proiect care trebuie gestionat în cadrul unui portofoliu de proiecte similare. Principalii parametri ai proiectului de control al problemei sunt prezentați în Tabelul 2.
|
Parametrul procesului |
Descriere |
|---|---|
|
Scop |
|
|
Proprietar | |
|
|
|
|
|
Parametri numerici tipici |
|
Intrarea într-un proces poate proveni din mai multe surse. În mod obișnuit, incidentele de mare severitate sunt escalate automat la procesul de gestionare a problemelor. În organizațiile cu un al doilea nivel de suport puternic, incidentele escalate la al treilea nivel de suport sunt, de asemenea, direcționate în mod obișnuit către procesul de control al problemelor. În sfârșit, întâlnirea zilnică poate redirecționa anumite incidente către procesele de control al problemelor. Procesul care implementează controlul problemelor este prezentat în Figura 2.

Figura 2. Modelul procesului de control al problemelor
Accentul procesului de control al problemei este determinarea cauzelor. Compoziția participanților la analiza cauzei și durata de timp necesară pentru a finaliza o astfel de analiză depind de problema în sine. Următoarele afirmații pot fi considerate corecte:
- Dacă aveți suficiente probleme, atunci desemnați o echipă permanentă. În caz contrar, creați o echipă atunci când apare o problemă, în același mod în care se formează o echipă pentru un proiect;
- Echipa ar trebui să aibă aproape întotdeauna experiență și cunoștințe interdisciplinare. Și acest lucru depinde desigur de natura problemei în cauză;
- O estimare a timpului pentru a determina cauza (elaborarea unui plan de proiect) ar trebui să fie dată atunci când apare problema. Progresul echipei ar trebui măsurat în raport cu această evaluare.
Odată ce resursele au fost alocate și prioritizate, mecanica reală de determinare a cauzei poate lua mai multe forme. Asemenea metode de căutare a cauzelor precum analiza Kepner și Trego, diagramele Ishikawa, diagramele Pareto etc. s-au dovedit bine.
Monitorizarea erorilor oferă documentarea metodelor de depășire a defecțiunilor și de alertare a personalului de asistență despre acestea (metode). Aceasta include și menținerea contactului cu alte organizații tehnice și de dezvoltare, ceea ce ajută și la identificarea erorilor. În plus, controlul erorilor îi influențează pe dezvoltatori să implementeze remedieri pentru erorile cunoscute. Tabelul 3 prezintă principalii parametri ai procesului de control al erorilor. Figura 3 prezintă un model al procesului de control al erorilor.
|
Parametrul procesului |
Descriere |
|---|---|
|
Scop |
|
|
Proprietar |
|
|
|
|
|
|
Parametri numerici tipici |
|

Figura 3. Modelul procesului de control al erorilor
Interacțiuni
De obicei, interacțiunile în acest proces iau una dintre cele două forme. Acestea sunt fie mesaje despre starea unui incident sau problemă, care sunt furnizate diferitelor grupuri și/sau indivizi pe baza unor reguli și șabloane aprobate, fie mesaje despre solicitări care solicită destinatarului să întreprindă anumite acțiuni, conținând de obicei, în plus față de cerere/cerere reală, un link către incident, numărul de telefon al utilizatorului sau alt link către acesta.
Multe companii se bazează pe capabilitățile de mesagerie automatizate oferite de software. Astfel de mesaje sunt trimise conform reglementărilor stricte pentru a menține escaladarea. Mesajele de stare de la sistemele software sunt generate de obicei din datele introduse în câmpurile de pe un card de incident. Prin urmare, astfel de mesaje sunt adesea incomplete și asemănătoare faptului că câmpurile utilizate pentru a construi mesaje automate pot fi actualizate neregulat cu informații în timp util sau populate automat de software de monitorizare folosind jargonul mesajelor de eroare.
Pentru a corecta aceste neajunsuri, capacitățile de comunicare automată sunt completate, mai ales în cazul incidentelor de mare gravitate, cu mesaje manuale.
Escaladare
Mecanism de escaladare Ajută la rezolvarea unui incident în timp util prin creșterea capacității personalului, a nivelului de efort și a priorității concentrate pe rezolvarea incidentului. Cele mai bune organizații au căi de escaladare bine definite, cu termene și responsabilități clar definite la fiecare pas. Ei folosesc mijloace gestionarea incidentelor pentru a transfera automat responsabilitatea la niveluri crescânde de suport în funcție de constrângerile de timp și de complexitate.
Perioadele de timp și responsabilitățile pentru escaladare variază foarte mult în funcție de organizație, industrie și nivelul de complexitate al problemelor. În organizațiile de conducere, discuțiile au loc cu utilizatorii finali pentru a determina intervalele de timp adecvate și escaladarea responsabilităților. Rezultatul unor astfel de negocieri este implementat sub formă de acorduri de nivel de serviciu, instrumente automate, liste și șabloane.
Escaladarea funcțională
Escaladarea funcțională există o escaladare a incidentului la un nivel superior de suport atunci când cunoștințele sau experiența sunt insuficiente sau intervalul de timp convenit a expirat. Organizațiile avansate definesc o matrice de niveluri de severitate bazată pe gradul de impact asupra afacerii, intervalul de timp pentru rezolvarea incidentului și intervalele de timp în care incidentul trebuie escaladat la o echipă mai avansată. Tabelul 4 reprezintă o astfel de matrice.
În majoritatea organizațiilor, grupurile de suport de primul și al doilea nivel sunt concentrate pe funcționarea infrastructurii existente, în timp ce al treilea nivel de sprijin este de obicei oferit de grupuri care sunt responsabile de planificarea dezvoltării infrastructurii și proiectarea acesteia. Prin urmare, planificarea atentă a modului în care responsabilitatea va fi transferată funcțional la al treilea nivel este critică.
|
Nivelul incidentului |
Descriere |
Termenul limită pentru decizie |
Primul nivel |
Prima escaladare |
A doua escaladare |
A treia escaladare |
|---|---|---|---|---|---|---|
|
Mai mult de 50 de utilizatori nu pot efectua tranzacții comerciale |
Primul nivel de suport |
Al 2-lea nivel de suport |
Nivelul 3 de suport |
Primul manager Întâlnire de urgență |
||
|
10 până la 49 de utilizatori nu pot efectua tranzacții comerciale |
Primul nivel de suport |
Al 2-lea nivel de suport |
Nivelul 3 de suport |
Primul manager Întâlnire de urgență |
||
|
1 până la 9 utilizatori nu pot efectua tranzacții comerciale |
Primul nivel de suport |
Al 2-lea nivel de suport |
Nivelul 3 de suport |
Primul manager |
În organizațiile avansate, un pager de serviciu este de obicei definit. Managerul fiecărui grup de tehnologie este responsabil pentru pregătirea unui program de gestionare a apelurilor primite pe un astfel de pager și de a se asigura că apelurile sunt deservite în orice moment. În plus, trebuie definită o procedură de escaladare ierarhică (managerială) pentru fiecare grup de tehnologie. De obicei, managerul de linie al echipei de nivel al treilea este primul lider în escaladare.
Escaladarea ierarhică
Pentru a se asigura că unui incident i se acordă prioritate corespunzătoare și că resursele necesare sunt alocate înainte de depășirea intervalului de timp pentru rezolvare, escaladarea ierarhică implică managementul în proces. Escalarea ierarhică poate fi efectuată la orice nivel de suport. În Tabelul 4, escaladarea ierarhică are loc în al treilea pas de escaladare pentru probleme de toate nivelurile de severitate.
În organizațiile avansate, escaladarea către management are loc automat conform unei proceduri predefinite bazate pe gravitatea problemei. Odată ce a avut loc o escaladare, se așteaptă ca managerul corespunzător să gestioneze în mod activ soluționarea problemelor și să devină punctul unic de contact pentru comunicările de stare.
Raportare și îmbunătățire a proceselor
Rapoartele statistice în organizațiile de vârf sunt utilizate pentru monitorizare, îmbunătățirea continuă a procesului și analiza indicatorilor de performanță în raport cu nivelul de serviciu convenit cu clienții.
Pentru controlul procesului gestionarea incidentelorși gestionarea problemelor poate utiliza, de exemplu, rapoarte care conțin valorile următorilor parametri:
- Numărul de carduri de incident deschise în prezent, defalcate pe nivel de importanță, timp petrecut, grupuri de responsabilitate
- Numărul de carduri cu probleme deschise în prezent (a căror cauză nu a fost încă identificată)
Astfel de rapoarte permit managerilor să ia decizii cu privire la alocarea resurselor și direcția eforturilor personalului. Utilizarea regulată a parametrilor de tip:
- Timp mediu de procesare a cardului la fiecare nivel
- Numărul de carduri trecute și rezolvate la fiecare nivel poate ajuta la identificarea punctelor slabe ale infrastructurii IT
În cele din urmă, un set vital de rapoarte, cum ar fi:
- Procentul de incidente rezolvate într-un interval de timp dat
- Timpul mediu de restabilire a serviciului permite organizațiilor IT să interacționeze cu consumatorii lor și să coreleze nivelul de performanță atins cu nivelul țintă de serviciu
Concluzie
Dezvoltarea proceselor si procedurilor gestionarea incidentelor este realizat de multe organizații, dar nu toate aceste organizații fac același lucru pentru gestionarea problemelor. Acest lucru se datorează adesea lipsei de înțelegere clară a caracteristicilor acestor două activități. este cea mai simplă activitate de înțeles deoarece pur și simplu creează un mecanism de răspuns la întreruperile serviciului. Întrucât „roata scârțâitoare va avea întotdeauna grăsimea”, gestionarea incidentelor evoluează destul de repede. Cu toate acestea, există adesea mai puține oportunități de a dezvolta managementul problemelor.
Managementul problemelor este mai mult ca gestionarea unui portofoliu de proiecte, fiecare având scopul de a identifica cauza unei probleme. Incidentele sunt adesea primul indicator al unei probleme și, odată ce se confruntă cu un incident, o organizație ar trebui să aibă un proces și proceduri pentru a determina cauza.
Continuând analogia portofoliului de proiecte, organizația de management al problemelor trebuie să dezvolte un criteriu de identificare a problemelor care ar trebui investigate pentru a determina cauzele, în același mod ca și pentru criteriul de decizie pentru alegerea unui nou proiect. Problemele care nu sunt cercetate continuă să fie monitorizate pentru cercetări viitoare. Odată ce o cauză este găsită și o soluție este dezvoltată, organizația urmărește progresul în implementarea soluției.
etc Procesele de management al incidentelor și managementul problemelor sunt similare în multe privințe, dar au și diferențe semnificative. Vom descrie fiecare dintre procese separat, apoi le vom compara din puncte de vedere diferite, discutând despre metodele de implementare.
Gestionarea incidentelor
Scopul principal al procesului de management al incidentelor este de a restabili funcționalitatea normală a sistemului cât mai repede posibil și de a minimiza impactul negativ asupra afacerii care utilizează serviciile care au fost întrerupte. „Funcționarea normală a serviciilor” înseamnă funcționarea în conformitate cu acordul de nivel de servicii (SLA).
Incidentele nu pot include evenimente care nu au legătură cu calitatea serviciilor IT furnizate, precum și cele care, deși reduc această calitate, nu depășesc domeniul de aplicare specificat în SLA. Un loc aparte îl ocupă cazurile în care clientul nu a simțit prezența unui incident (de exemplu, dacă toate măsurile necesare au fost luate automat sau de către personalul de service chiar înainte ca calitatea să scadă efectiv). Exemple: arhivarea automată a datelor și eliberarea discului scratch atunci când acesta se apropie de punctul de overflow; trecerea la un server de rezervă dacă cel principal eșuează etc. Cu toate acestea, astfel de cazuri nu pot fi excluse din lista incidentelor. Organizarea adecvată necesită gestionarea acestor incidente în conformitate cu procedura completă (adică, afișarea lor ulterioară în rapoarte și luarea măsurilor necesare pentru a le preveni în viitor).
Fiecare proces de management al incidentelor poate fi descris în mod formal prin enumerarea unui set de caracteristici.
Datele de intrare pentru descrierea incidentelor sunt:
- o descriere detaliată a incidentului primit de la Service Desk, servicii de asigurare a funcționării operaționale a rețelelor sau serverelor etc.;
- descrierea configurațiilor și elementelor eventual legate de incident. Descrierile sunt preluate din CMDB, o bază de date de unități de configurare care include toate elementele infrastructurii IT (hardware, software, documentație, servicii furnizate etc.);
- informații (dacă sunt disponibile) din baza de date cu probleme și din baza de date a erorilor cunoscute;
- descrierea metodei de rezoluție.
Rezultatul procesului de management al incidentelor ar putea fi:
- o cerere de modificări temporare pentru a rezolva incidentul, o înregistrare actualizată a incidentului, inclusiv o soluție și/sau o soluție;
- incident rezolvat (rezolvat) și închis;
- mesaj către client;
- informatii de management (raport).
Activități posibile de gestionare a incidentelor:
- identificarea și înregistrarea unui incident;
- clasificarea incidentelor si asistenta initiala;
- cercetare și diagnosticare;
- rezolvarea incidentelor și recuperarea sistemului;
- închiderea incidentului;
- proprietate, monitorizare, urmărire și interacțiune.
Roluri și funcții de gestionare a incidentelor:
- echipele de suport din prima, a doua și a treia linie, precum și echipele de specialitate și partenerii externi (roluri); manager de management al incidentelor (rol); Manager Service Desk (funcție).
Valori posibile:
- numărul total de incidente;
- timpul mediu pentru rezolvarea sau ocolirea unui incident pentru diferite tipuri de incidente;
- procentul de incidente rezolvate într-o perioadă de timp care nu depășește cea specificată în SLA;
- costul mediu de rezolvare a unui incident;
- procentul de incidente închise fără implicarea altor specialiști;
- numărul și procentul de incidente rezolvate de la distanță (fără a vizita utilizatorul).
Pentru a asigura respectarea intervalului de timp alocat pentru implementarea anumitor acțiuni, se utilizează escaladarea funcțională și ierarhică. „Escaladare” se referă la un mecanism organizațional care ajută la controlul timpului de rezolvare a unui incident; ar trebui utilizat în toate activitățile din timpul procesului de rezolvare a incidentelor. Esența acestuia constă în necesitatea fie de a transfera obligatoriu informații despre incident către specialiști mai calificați, fie de a informa conducerea despre imposibilitatea eliminării incidentului în intervalul de timp convenit.
Transferul unui incident de la Service Desk pe o a doua linie de suport (escaladare funcțională) este necesară dacă este imposibil să rezolvi incidentul pe prima linie. Este posibilă escaladarea funcțională automată, dar trebuie planificată cu atenție în conformitate cu SLA.
Escaladarea ierarhică este necesară atunci când este imposibil de rezolvat incidentul fie în timpul alocat, fie cu calitatea cerută. De regulă, este efectuat manual de către personalul Service Desk, în funcție de experiența acestora. Se folosește și escaladarea ierarhică automată și poate fi construită pe baza ținând cont de intervale de timp. Este recomandabil ca acesta să fie efectuat înainte de ora specificată în SLA; aceasta va oferi managerului relevant oportunitatea de a lua măsuri suplimentare.
Efectul implementării unui proces de management al incidentelor
Să enumeram cele mai importante calități utile care sunt dobândite ca urmare a implementării procesului de management al incidentelor. Pentru afaceri în general, acesta este:
- reducerea impactului negativ al incidentelor asupra afacerii, realizată prin creșterea eficienței și reducerea timpului necesar pentru rezolvarea acestora;
- determinarea proactivă (anticipativă) a necesității extinderii și corectării sistemelor critice pentru afaceri;
- Disponibilitatea informațiilor de management necesare afacerii, corelate cu condițiile SLA.
Munca departamentului IT dobândește și o serie de calități utile:
- monitorizare avansată pentru a măsura performanța față de SLA;
- informații îmbunătățite pentru managementul calității serviciilor;
- utilizarea mai optimă a personalului și munca mai eficientă;
- eliminarea pierderilor și înregistrarea incorectă a incidentelor și solicitărilor;
- întreținerea mai precisă a bazei de date a unității de configurare CMDB;
- o mai bună satisfacție a clienților.
Lucrul fără un sistem de management al incidentelor poate duce la o serie de probleme. Absența persoanelor responsabile pentru rezolvarea și escaladarea incidentelor duce la confuzie în rezolvarea defecțiunilor și reduce calitatea serviciului. Specialiștii serviciilor de asistență sunt distrași de la sarcinile lor, ceea ce reduce eficiența muncii lor. Pentru a rezolva incidente și probleme, utilizatorii sunt nevoiți să comunice între ei, distrași de la principalele lor responsabilități. De fiecare dată trebuie să reanalizezi incidentele – chiar și cele care apar în mod regulat și ar trebui cunoscute.
Managementul problemelor
Scopul principal al procesului de management al problemelor este de a minimiza impactul negativ asupra activității de bază a organizației al incidentelor și problemelor rezultate din erorile din infrastructura IT și de a preveni reapariția incidentelor asociate cu aceste erori. Pentru a face acest lucru, se caută și se clarifică cauzele incidentelor și se întreprind acțiuni pentru îmbunătățirea situației sau eliminarea cauzelor identificate.
Procesul de management al problemelor este atât reactiv, cât și proactiv. Prima opțiune se referă la rezolvarea problemelor asociate cu incidentele apărute, a doua are ca scop identificarea și eliminarea problemelor care ar putea duce la, dar nu au condus încă la, incidente.
Controlul problemelor și erorilor, împreună cu managementul proactiv al problemelor, sunt responsabilitățile procesului de management al problemelor. În limbajul definițiilor formale, o „problemă” este o cauză principală necunoscută a unuia sau mai multor incidente, iar o „eroare cunoscută” este o problemă diagnosticată cu succes pentru care a fost găsită o soluție sau o soluție.
În ceea ce privește procesul de management al incidentelor, prezentăm grupuri de caracteristici principale ale procesului de management al problemelor. Deși unele dintre ele sunt aceleași, este logic să le enumeram pe toate, deoarece vorbim despre procese diferite.
Datele de intrare pentru descriere sunt:
- detalii despre incident derivate din gestionarea incidentelor;
- descrierea detaliată a configurațiilor din CMDB;
- toate soluțiile cunoscute (de la gestionarea incidentelor).
Evenimente posibile:
- controlul problemelor și erorilor;
- prevenirea proactivă a problemelor;
- identificarea tendințelor;
- analiza informatiilor acumulate si intocmirea rapoartelor;
- pregătirea informațiilor de management.
Rezultatele pot fi după cum urmează:
- descrierea noilor erori cunoscute;
- cereri de modificare;
- un jurnal de probleme actualizat, inclusiv o posibilă soluție la problemă și/sau orice soluție disponibilă;
- pentru problemele rezolvate, jurnalul de probleme închis;
- căutarea de analogi ai incidentului printre erorile cunoscute și problemele luate în considerare;
- informatii de management.
Roluri și funcții: angajați responsabili cu gestionarea problemelor (rolurilor); Manager de management al problemelor (rol).
Valori posibile:
- numărul de solicitări de modificare inițiate și impactul acestor solicitări asupra fiabilității și disponibilității serviciilor pe care le acoperă;
- timpul alocat lucrărilor de cercetare și diagnosticare pentru fiecare departament, ținând cont de împărțirea în tipuri de probleme;
- numărul și impactul incidentelor care au avut loc înainte de identificarea cauzei problemei sau înainte de raportarea unei erori cunoscute;
- raportul dintre volumul eforturilor pentru asistență și sprijin imediat și cele planificate;
- numărul de probleme și erori grupate după diverse criterii (stare, servicii, impact, categorii, grupuri de utilizatori);
- Timpul mediu și maxim petrecut pentru închiderea unei probleme sau reconcilierea unei probleme cunoscute, calculat din momentul raportării problemei, grupat pe coduri de impact și grupuri de suport;
- timpul estimat pentru rezolvarea problemelor deschise;
- timpul total petrecut cu toate problemele închise.
Efectul implementării unui proces de management al problemelor
Să enumeram cele mai importante calități utile care sunt dobândite ca urmare a implementării procesului de management al problemelor.
- Calitatea serviciilor. Managementul problemelor ajută la menținerea unui ciclu continuu de îmbunătățire continuă a calității serviciilor IT.
- Reducerea numărului de incidente. Procesul de management al problemelor este un instrument de reducere a numărului de incidente care au loc și care au un impact negativ asupra afacerii unei organizații.
- Soluție continuă. Ca rezultat al procesului, numărul și impactul asupra afacerii problemelor deja rezolvate și erorilor cunoscute sunt reduse.
- Antrenament avansat. Procesul se bazează pe conceptul de utilizare a cunoștințelor acumulate din trecut și oferă oportunități de a analiza tendințele și de a preveni întreruperile sau de a reduce semnificația și impactul acestora asupra activității de bază.
- Creșterea numărului de incidente rezolvate la primul apel. Acest lucru se realizează prin furnizarea Biroului de service cu recomandări cu privire la modul de prevenire și rezolvare a incidentelor care apar.
La rândul său, refuzul de a implementa procesul promite o serie de probleme. Serviciul de asistență pur „ex-post” începe să funcționeze numai atunci când serviciul nu mai este disponibil. Se dezvoltă o infrastructură care impune utilizatorilor să folosească instrumentele IT în mod independent. Echipele de suport ineficiente, costisitoare și slab motivate rezolvă aceleași probleme din nou și din nou, fără a ține cont de experiența anterioară.
Implementare și implementare
Am atras deja atenția asupra principalei diferențe dintre procesele luate în considerare, care a fost luată în considerare la formarea unor indicatori cheie de calitate. Scopul managementului incidentelor este de a rezolva incidentele cât mai repede posibil. Managementul problemelor ar trebui să excludă posibilitatea reapariției unui incident din aceleași motive (și uneori din aceleași motive).
Din punct de vedere organizatoric, aceasta înseamnă că nimeni nu poate îndeplini responsabilități pentru ambele procese în același timp, deoarece nu ar fi capabil să prioritizeze corect. Ca o cale de ieșire din situația cu personalul tradițional limitat, se recomandă definirea clară în instrucțiuni a unui timp sau alt cadru care să permită unui specialist să îndeplinească clar un rol doar într-unul dintre procese. De exemplu, un angajat al serviciului de operare a rețelei al băncii, în perioadele critice pentru efectuarea plăților majore, este obligat, dacă apar eșecuri, să ia toate măsurile pentru a elimina aceste defecțiuni cât mai repede posibil și a restabili funcționalitatea sistemelor, jucând rolul unui specialist în managementul incidentelor. În momente relativ mai puțin critice, acestui specialist îi este interzis să răspundă la incidente emergente și i se ordonă să analizeze informațiile acumulate despre defecțiuni și să caute cauzele acestora și, prin urmare, să ia măsuri de gestionare a problemelor.
Este acceptabil (și recomandat) să combinați funcțiile Service Desk și funcțiile de gestionare a incidentelor. Cu toate acestea, este important să ne amintim că acestea sunt procese diferite: comunicarea inițială cu utilizatorii nu face parte din procesul de management al incidentelor. În plus, utilizatorul poate contacta serviciul de asistență nu numai în legătură cu un incident, ci și dintr-un alt motiv (nevoie de informare, nevoie de reîncărcare consumabile etc.). Pe de altă parte, cu unele metode de implementare (de exemplu, în cazul construirii unui serviciu de asistență bazat pe tehnologii Web, când utilizatorul introduce în mod independent toate datele necesare în formulare), necesitatea unui Service Desk dedicat este discutabilă. În același timp, în niciun caz nu trebuie să refuzi gestionarea incidentelor - indiferent de unde vine mesajul despre apariția lor, cineva trebuie să fie responsabil pentru eliminarea lor.
Este clar că implementarea managementului problemelor în absența managementului incidentelor este practic imposibilă: baza și sursa datelor pentru luarea în considerare a problemei o constituie informațiile acumulate în timpul analizei și procesării incidentelor. Uneori este acceptabil să se implementeze doar managementul incidentelor. De obicei, companiile intermediare nu au probleme de management - având propriul serviciu de expediere, astfel de companii organizează recepția și înregistrarea cererilor clienților, îi ajută, dacă este posibil, să rezolve incidentul cu ajutorul consultării, transferă cereri mai complexe către subcontractanți și controlează. acțiunile lor, implementând astfel managementul incidentelor. În același timp, ei nu analizează problemele, deoarece nu sunt organizația efectivă de funcționare. Gestionarea problemelor este adesea exclusă chiar dacă nu există nicio oportunitate sau dorință de a face acest lucru. În unele cazuri, se recomandă chiar implicarea unor specialiști externi pentru a analiza problemele, deoarece acest lucru necesită calificări foarte înalte, precum și echipamente scumpe. Un exemplu sunt contactele tradiționale cu companii specializate în construcția și întreținerea telecomunicațiilor pentru a determina sarcina reală a rețelelor de date: echipamentul corespunzător este scump, iar necesitatea utilizării acestuia apare extrem de rar.
Pentru instrumentele de automatizare, ITIL recomandă, cel puțin, capabilități de integrare profundă între instrumentele de gestionare a problemelor și incidentelor. Într-adevăr, atunci când se analizează probleme, este important să se poată analiza toate incidentele raportate din perspective diferite. La rândul lor, pentru a comunica mai eficient cu utilizatorii atunci când apar noi incidente, specialiștii relevanți au nevoie de acces la problemele în așteptare sau deja închise și la erorile cunoscute.
Acest lucru poate fi ușor de înțeles folosind următoarea situație ca exemplu. Un utilizator contactează asistența cu un mesaj despre o creștere bruscă a timpului de răspuns de la server. Operatorul, căutând prin lista problemelor analizate, găsește o înregistrare a lucrărilor efectuate pentru a analiza scăderea performanței serverului, după care informează utilizatorul că mesajul său a fost înregistrat și are legătură cu problema luată în considerare, iar eliminarea este de așteptat. după o anumită perioadă de timp, despre care utilizatorul va fi informat suplimentar. În absența capacității de a vizualiza o listă de probleme, operatorul nu ar putea să asocieze incidentul cu problema analizată în mod specific, apoi să urmărească rapid faptul că a fost rezolvată și să informeze utilizatorul despre aceasta.
Producătorii de scule încearcă să țină cont de recomandările menționate. De exemplu, HP OpenView Service Desk 3.0 are o structură modulară. Capacitatea de a înregistra și gestiona solicitările utilizatorilor, incidentele și problemele este implementată ca un modul separat, care este pe deplin în concordanță cu recomandările menționate: integrarea în acest caz este cât se poate de completă. Utilizatorii unui sistem construit pe baza acestui produs au posibilitatea de a construi conexiuni între înregistrările de înregistrare de toate tipurile enumerate, de a căuta după context și, ținând cont de aceste conexiuni, de a determina metode cunoscute de rezolvare a problemelor emergente. Separarea acestor funcții poate reduce eficiența instrumentului și, ca urmare, calitatea implementării proceselor. Totodată, baza oricărei soluții de management al infrastructurii IT este luarea în considerare a echipamentelor existente, aplicațiilor, documentației etc. - tot ceea ce alcătuiește această infrastructură. Aceste capabilități sunt disponibile și ca parte a HP Service Desk 3.0. În plus, caracteristicile concepute pentru a automatiza managementul schimbărilor și managementul SLA sunt implementate ca module separate. Integrarea tuturor modulelor de mai sus este implementată în cea mai mare măsură posibilă, oferind posibilitatea de a utiliza produsul în cauză ca bază pentru construirea unui sistem cuprinzător de management IT.
Produsul Remedy este construit ceva mai complex; se bazează pe sistemul Remedy Action Request, instalat pe server. Module funcționale suplimentare pot fi achiziționate ca parte a aplicației din sistem: Help Desk, Asset Management, Change Management și Service Level Agreement. Fiecare dintre module poate fi utilizat fie independent (fără alte module de aplicație), fie ca parte a unei soluții integrate. Problemele de automatizare a proceselor de gestionare a problemelor și incidentelor, ca în cazul soluției HP, sunt implementate în modulul Remedy Help Desk. În același timp, există unele diferențe și sunt implementate abordări individuale pentru înțelegerea acestor procese, dar principalele dorințe și cerințe ale ITIL sunt pe deplin luate în considerare.
Pentru implementarea cu succes a proceselor de management al incidentelor și problemelor
Trebuie îndeplinite cel puțin următoarele condiții.
- Disponibilitatea unei baze de date CMDB actuale și actualizate în timp util. Dacă această bază de date nu este disponibilă, informațiile despre elementele de configurare legate de incident vor fi preluate manual, ceea ce va crește semnificativ timpul de procesare a incidentului și va crește complexitatea acestuia.
- Disponibilitatea unei baze de cunoștințe actualizate cu privire la erori/probleme și modalități de rezolvare și rezolvare a acestora. Având o astfel de bază de date, puteți rezolva rapid multe probleme. Este de dorit să se poată conecta la el baze de date similare dezvoltate de alte organizații și companii. Problemele de compatibilitate care apar pot duce la o mare complexitate, de aceea se recomanda utilizarea solutiilor de arhitectura deschisa care sa includa instrumente de import si export de date. Recent, interfața Web, care este convenabilă și de înțeles, precum și răspândită, este din ce în ce mai folosită ca metodă standard de accesare a informațiilor.
- Având în vedere potențialul conflict între managementul problemelor și managementul incidentelor (datorită diferitelor obiective ale acestora), este necesar să se organizeze lucrul comun și cooperarea între executanții ambelor procese. În același timp, nu trebuie să uităm că din aceleași motive una și aceeași persoană nu poate îndeplini ambele sarcini în același timp: îi va fi foarte greu să găsească un echilibru de interese.
- Organizarea unui sistem eficient de înregistrare automată a incidentelor cu capabilități de clasificare detaliate și de înaltă calitate, care reprezintă un element extrem de important pentru organizarea funcționării atât a serviciului Service Desk, cât și a proceselor în cauză în forma lor pură. Utilizarea tehnologiilor hârtiei în aceste scopuri nu este recomandată.
Este foarte convenabil dacă instrumentele utilizate pentru implementarea proceselor în cauză au următoarele capacități suplimentare:
- înregistrarea automată a incidentelor apărute în cele mai importante dispozitive (servere, echipamente de rețea etc.), care pot necesita crearea de interfețe suplimentare;
- escaladarea automată a incidentelor în cazul încălcării orarelor;
- rutare flexibilă a incidentelor, deoarece personalul de asistență poate fi amplasat în diferite încăperi și clădiri;
- căutarea automată a datelor necesare în baza de date CMDB;
- soluții speciale pentru a facilita clasificarea incidentelor;
- integrare cu sistemele de telefonie;
- prezența diferitelor module de diagnosticare.
Să ilustrăm capabilitățile enumerate folosind exemplul deja menționat Service Desk 3.0. Ca membru al familiei de produse HP OpenView, Service Desk include posibilitatea de a primi mesaje de la alte produse din familie, inclusiv Network Node Manager, un instrument pentru monitorizarea și gestionarea dispozitivelor de rețea și VantagePoint Operations, un instrument de monitorizare și gestionare. servere și aplicații. Aceste produse pot genera automat, pe baza informațiilor colectate despre obiectele monitorizate, cereri pentru Service Desk, care sunt transmise și analizate automat de operatorii de servicii de asistență sau procesate automat. Cu setări adecvate, alte instrumente de diagnosticare pot deveni, de asemenea, surse de mesaje similare. Produsul oferă posibilitatea de a informa automat prin trimiterea de mesaje managerilor la nivelurile corespunzătoare dacă termenele limită pentru rezolvarea unui incident sunt încălcate. Implementează capabilități avansate de căutare a informațiilor necesare printre problemele, incidentele și alte date deja înregistrate. Produsul oferă capabilități de integrare cu sisteme de poștă, telefon și paginare.
Având în vedere relevanța și utilitatea caracteristicilor suplimentare enumerate, producătorii de soluții software încearcă să le includă în produsele lor. Multe din ceea ce s-a spus despre HP Service Desk se aplică și produselor de la alți producători, inclusiv Remedy, Tivoli, CA, Peregrin, FrontRange.
Cei care întreprind munca de implementare a proceselor luate în considerare trebuie să fie pregătiți pentru o varietate de dificultăți. Printre ei:
- lipsa de sprijin din partea conducerii și a personalului, ceea ce poate duce la o lipsă de resurse pentru implementare;
- lipsa de înțelegere a nevoilor afacerii, lipsa nivelurilor de servicii convenite, obiective prost definite, capacități și responsabilități ale diferitelor servicii;
- rezistența la schimbare și incapacitatea de a face modificări practicilor de lucru existente;
- lipsa de cunoștințe pentru rezolvarea incidentelor, pregătirea necorespunzătoare a personalului, regulile slab formalizate pentru interacțiunea utilizatorilor cu serviciile de asistență și diverse servicii între ei;
- integrarea slabă cu alte procese, instrumente de automatizare de calitate scăzută și incapacitatea de a lega înregistrările de înregistrare a incidentelor și problemele corespunzătoare reduc semnificativ capacitățile procesului, inclusiv capacitatea de a prezice probleme.
***
Ne-am concentrat pe două dintre cele mai frecvent citate procese de management IT atunci când vine vorba de depanare. Deși destul de ușor de înțeles la nivel intuitiv, aceste procese sunt greu de implementat din punctul de vedere al necesității respectării stricte a măsurilor și procedurilor organizaționale. Deși similare în multe privințe, procesele de gestionare a incidentelor și de gestionare a problemelor au, de asemenea, diferențe semnificative care decurg din obiectivele lor principale. La implementarea proceselor, instrumentele de automatizare utilizate în aceste scopuri devin de maximă importanță. Din păcate, sursele primare pe ITIL sunt disponibile unui cerc foarte restrâns de persoane interesate: sunt foarte scumpe, comandarea lor nu este ușoară, iar obținerea lor este și mai dificilă. Cerințele și dorințele pentru instrumentele expuse în articol se bazează pe experiența reală în operarea diverselor instrumente și pe o analiză a modalităților de rezolvare a problemelor apărute.
Literatură
1. Z. Alekhine. ITIL este baza conceptului de management al serviciilor IT. „Sisteme deschise”. 2001, nr. 3
2. Z. Alekhine. Service Desk - obiective, capabilități, implementare. „Sisteme deschise”. 2001, nr. 5-6
3. CCTA. Cele mai bune practici pentru Service Support. Londra: The Stationery Office, 2000
Zaurbek Alekhine ([email protected]) - manager de proiect la i-Teco (Moscova).
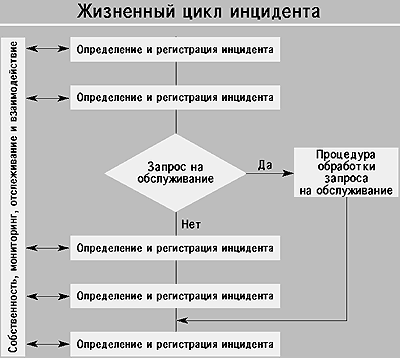
Ce este un incident
Conform definiției ITIL a "incident" se înțelege ca „orice eveniment care nu este un element al funcționării normale a serviciului și, în același timp, are sau este capabil să afecteze prestarea serviciului prin întreruperea acestuia sau diminuarea calității acestuia”.
Aplicatii:
- Serviciu indisponibil;
- o eroare în aplicație care împiedică clientul să funcționeze normal;
- Spațiul pe disc este epuizat.
Echipament:
- eroare de sistem;
- alarma interna;
- defecțiune a imprimantei.
Cereri de servicii:
- primirea unei cereri pentru informații suplimentare, sfaturi, documentații;
- parola uitata.
Majoritatea echipelor IT sunt implicate în rezolvarea unui tip de incident. Serviciul de service este responsabil pentru monitorizarea soluționării tuturor incidentelor raportate, deoarece este proprietarul tuturor acestor incidente. Acest proces este în mare măsură reactiv; Pentru a răspunde eficient la incidente, trebuie definit un mod formal de lucru pentru angajați, inclusiv utilizarea software-ului necesar.
Acele incidente care nu pot fi rezolvate direct de către Biroul de Asistență trebuie să fie transmise specialiștilor corespunzători. O metodă pentru rezolvarea unui incident sau a unei soluții ar trebui stabilită și comunicată utilizatorilor cât mai repede posibil. Acest lucru rezultă din scopul principal - de a minimiza impactul negativ asupra activităților principale ale utilizatorilor. După ce cauza incidentului a fost eliminată și serviciul a fost restabilit la nivelul specificat în SLA, incidentul este închis.
Asigurarea securității informațiilor de afaceri Andrianov V.V.
4.1.4. Exemple de incidente
4.1.4. Exemple de incidente
Informații generale
Această secțiune descrie detalii publicate ale unora dintre incidentele importante. În același timp, generalizarea incidentelor oferă o grămadă de circumstanțe care caracterizează varietatea de amenințări la securitatea informațiilor din partea personalului, atât în ceea ce privește motivele și condițiile, cât și în ceea ce privește mijloacele utilizate. Printre incidentele cele mai frecvente, remarcăm următoarele:
Scurgeri de informații oficiale;
Furtul clienților și afacerilor organizației;
Sabotajul infrastructurii;
fraudă internă;
Falsificarea rapoartelor;
Tranzacționarea pe piețe pe baza informațiilor privilegiate și de proprietate;
Abuz de autoritate.
adnotare
Ca răzbunare pentru un bonus prea mic, Roger Duronio, în vârstă de 63 de ani (fost administrator de sistem la UBS Paine Webber) a instalat o „bombă logică” pe serverele companiei, care a distrus toate datele și a paralizat mult timp munca companiei.
Descrierea incidentului
Duronio era nemulțumit de salariul său de 125.000 de dolari pe an, care ar fi putut fi motivul introducerii bombei logice. Cu toate acestea, ultima picătură pentru administratorul de sistem a fost bonusul pe care l-a primit în valoare de 32.000 USD în loc de cei așteptați 50.000 USD. Când a descoperit că bonusul său era mult mai mic decât se aștepta, Duronio i-a cerut șefului său să-și renegocieze contractul de muncă la 175.000 de dolari pe an, altfel va părăsi compania. I s-a refuzat o creștere de salariu și i s-a cerut și să părăsească clădirea băncii. Ca răzbunare pentru un astfel de tratament, Duronio a decis să-și folosească „invenția”, introdusă în prealabil, anticipând o astfel de întorsătură a evenimentelor.
Duronio a implementat „bomba logică” de pe computerul său de acasă cu câteva luni înainte de a primi ceea ce el considera a fi un bonus prea mic. Bomba logică a fost instalată pe aproximativ 1.500 de calculatoare dintr-o rețea de sucursale din toată țara și setată la o oră anume - 9.30, exact la timp pentru începerea zilei bancare.
Duronio a demisionat de la UBS Paine Webber pe 22 februarie 2002, iar pe 4 martie 2002, o bombă logică a șters secvențial toate fișierele de pe serverul principal al bazei de date și 2.000 de servere din cele 400 de sucursale ale băncii, în timp ce a dezactivat sistemul de rezervă.
În timpul procesului, avocatul lui Duronio a subliniat că vinovatul incidentului nu ar fi putut fi singur acuzatul: având în vedere nesiguranța sistemelor IT UBS Paine Webber, orice alt angajat ar fi putut ajunge acolo sub login-ul lui Duronio. Problemele cu securitatea IT la bancă au devenit cunoscute încă din ianuarie 2002: în timpul unui audit, s-a constatat că 40 de persoane din serviciul IT se puteau conecta în sistem și puteau obține drepturi de administrator folosind aceeași parolă și să înțeleagă cine exact a făcut-o sau oricare. altă acțiune nu a fost posibilă. Avocatul a mai acuzat-o pe UBS Paine Webber și compania @Stake, angajată de bancă să investigheze incidentul, că au distrus dovezile atacului. Cu toate acestea, dovada de nerefuzat a vinovăției lui Duronio au fost bucățile de cod rău intenționat găsite pe computerele sale de acasă și o copie tipărită a codului din dulapul lui.
Oportunități din interior
Ca unul dintre administratorii de sistem ai companiei, Duronio a primit responsabilitatea și accesul la întreaga rețea de calculatoare UBS PaineWebber. De asemenea, avea acces la rețea de pe computerul său de acasă printr-o conexiune securizată la internet.
Cauze
După cum am spus mai devreme, motivele lui au fost banii și răzbunarea. Duronio a primit un salariu anual de 125.000 de dolari și un bonus de 32.000 de dolari, în timp ce se aștepta la 50.000 de dolari, și astfel și-a răzbunat dezamăgirea.
În plus, Duronio a decis să facă bani din atac: anticipând o scădere a acțiunilor băncii din cauza unui dezastru IT, a făcut un ordin futures de vânzare pentru a primi diferența atunci când cursul a scăzut. Inculpatul a cheltuit 20.000 de dolari pentru asta. Totuși, titlurile băncii nu au căzut, iar investițiile lui Duronio nu au dat roade.
Consecințe
„Bomba logică” instalată de Duronio a oprit activitatea a 2.000 de servere din 400 de birouri ale companiei. Potrivit managerului IT UBS Paine Webber, Elvira Maria Rodriguez, a fost un dezastru „un peste 10 pe o scară de 10”. Haosul a domnit în companie, care au avut nevoie de 200 de ingineri de la IBM pentru a-i elimina timp de aproape o zi. În total, aproximativ 400 de specialiști au lucrat pentru a corecta situația, inclusiv serviciul IT al băncii însuși. Prejudiciul cauzat de incident este estimat la 3,1 milioane de dolari. Opt mii de brokeri din toată țara au fost forțați să nu mai lucreze. Unii dintre ei au reușit să revină la operațiunile normale după câteva zile, alții după câteva săptămâni, în funcție de cât de grav au fost afectate bazele lor de date și dacă filiala băncii avea copii de rezervă. În general, operațiunile bancare au fost reluate în câteva zile, dar unele servere nu au fost niciodată complet restaurate, în mare parte din cauza faptului că 20% dintre servere nu aveau facilități de backup. Doar un an mai târziu, întregul parc de servere al băncii a fost complet restaurat din nou.
În timpul procesului lui Duronio în instanță, el a fost acuzat de următoarele acuzații:
Frauda cu valori mobiliare - Această acuzație implică o pedeapsă maximă de 10 ani de închisoare federală și o amendă de 1 milion de dolari;
Fraudă informatică - Această acuzație implică o pedeapsă maximă de 10 ani de închisoare și o amendă de 250.000 USD.
Ca urmare a procesului de la sfârșitul lui decembrie 2006, Duronio a fost condamnat la 97 de luni fără eliberare condiționată.
„VimpelCom” și „Sherlock”
adnotare
În scop de profit, foști angajați ai companiei VimpelCom (marca comercială Beeline) au oferit detalii despre convorbirile telefonice ale operatorilor de telefonie mobilă prin intermediul site-ului.
Descrierea incidentului
Angajații companiei VimpelCom (fostă și actuală) au organizat pe internet site-ul www.sherlok.ru, despre care compania VimpelCom a aflat în iunie 2004. Organizatorii acestui site au oferit un serviciu - căutarea persoanelor după nume, număr de telefon și alte date. În iulie, organizatorii site-ului au oferit un nou serviciu - detalierea convorbirilor telefonice ale operatorilor de telefonie mobilă. Detalierea apelurilor este o imprimare a numerelor tuturor apelurilor primite și efectuate, care indică durata apelurilor și costul acestora, utilizată de operatori, de exemplu, pentru facturarea abonaților. Pe baza acestor date, putem trage o concluzie despre activitățile curente ale abonatului, domeniul său de interes și cercul de cunoștințe. Comunicatul de presă al Direcției „K” a Ministerului Afacerilor Interne (denumit în continuare Ministerul Afacerilor Interne) clarifică faptul că o astfel de informație costă clientul 500 USD.
Angajații companiei VimpelCom, după ce au descoperit acest site, au colectat în mod independent dovezi ale activităților criminale ale site-ului și au transferat cazul Ministerului Afacerilor Interne. Angajații Ministerului Afacerilor Interne au deschis un dosar penal și, împreună cu firma VimpelCom, au stabilit identitățile organizatorilor acestei afaceri criminale. Și la 18 octombrie 2004, principalul suspect 1 a fost reținut în flagrant.
În plus, la 26 noiembrie 2004, restul de șase suspecți au fost reținuți, inclusiv trei angajați ai serviciului de abonați al companiei VimpelCom însăși. În timpul investigației, s-a dovedit că site-ul a fost creat de un fost student al Universității de Stat din Moscova, care nu a lucrat pentru această companie.
Hârtiile privind acest incident au devenit posibile datorită deciziei Curții Constituționale din 2003, care a recunoscut că detaliile convorbirilor conțin secretul convorbirilor telefonice, protejat de lege.
Oportunități din interior
Doi dintre angajații VimpelCom identificați printre participanții la incident lucrau ca casier în companie, iar al treilea era un fost angajat și lucra la piața Mitinsky în momentul crimei.
Lucrul ca casier în cadrul companiei indică faptul că acești angajați aveau acces direct la informațiile oferite spre vânzare pe site-ul www.sherlok.ru. În plus, întrucât un fost angajat al companiei a lucrat deja pe piața Mitinsky, se poate presupune că, în timp, această piață ar putea deveni și unul dintre canalele de distribuție pentru aceste informații sau orice alte informații din bazele de date ale companiei VimpelCom.
Consecințe
Principalele consecințe pentru VimpelCom ale acestui incident ar putea fi o lovitură adusă reputației companiei în sine și pierderea clienților. Cu toate acestea, acest incident a fost făcut public direct datorită acțiunilor active ale companiei însăși.
În plus, publicarea acestor informații ar putea avea un impact negativ asupra clienților VimpelCom, deoarece detaliile conversațiilor ne permit să tragem o concluzie despre activitățile curente ale abonatului, domeniul său de interes și cercul de cunoștințe.
În martie 2005, Tribunalul Districtual Ostankino din Moscova i-a condamnat pe suspecți, inclusiv trei angajați ai companiei VimpelCom, la diverse amenzi. Astfel, organizatorul grupului a fost amendat cu 93.000 de ruble. Cu toate acestea, funcționarea site-ului www.sherlok.ru a fost oprită pe termen nelimitat abia de la 1 ianuarie 2008.
Cea mai mare scurgere de date personale din istoria Japoniei
adnotare
În vara lui 2006, a avut loc cea mai mare scurgere de date cu caracter personal din istoria Japoniei: un angajat al gigantului de tipar și electronice Dai Nippon Printing a furat un disc cu informații private de aproape nouă milioane de cetățeni.
Descrierea incidentului
Compania japoneză Dai Nippon Printing, specializată în producția de produse tipărite, a permis cea mai mare scurgere din istoria țării sale. Hirofumi Yokoyama, un fost angajat al unuia dintre contractorii companiei, a copiat datele personale ale clienților companiei pe un hard disk mobil și le-a furat. Un total de 8,64 milioane de persoane au fost în pericol, deoarece informațiile furate includ nume, adrese, numere de telefon și numere de card de credit. Informațiile furate au inclus informații despre clienți de la 43 de companii diferite, cum ar fi 1.504.857 clienți American Home Assurance, 581.293 clienți Aeon Co și 439.222 clienți NTT Finance.
După furtul acestor informații, Hirofumi a deschis comerț cu informații private în porțiuni din 100.000 de înregistrări. Datorită veniturilor stabile, insiderul și-a părăsit chiar locul de muncă permanent. Până la arestarea sa, Hirofumi reușise să vândă datele a 150.000 de clienți ai celor mai mari firme de credit unui grup de escroci specializați în achiziții online. În plus, unele dintre date au fost deja folosite pentru fraudă cu cardul de credit.
Mai mult de jumătate dintre organizațiile cărora le-au fost furate datele clienților nici măcar nu au fost avertizate cu privire la scurgerea de informații.
Consecințe
În urma acestui incident, pierderile cetățenilor care au suferit din cauza fraudei cu cardul de credit, care au devenit posibile doar ca urmare a acestei scurgeri, s-au ridicat la câteva milioane de dolari. În total, clienții a 43 de companii diferite au fost afectați, inclusiv Toyota Motor Corp., American Home Assurance, Aeon Co și NTT Finance. Cu toate acestea, mai mult de jumătate dintre organizații nici măcar nu au fost avertizate cu privire la scurgere.
În 2003, Japonia a adoptat Legea privind protecția informațiilor cu caracter personal din 2003 (PIPA), dar procurorii nu au putut să o aplice în procesul propriu-zis al cazului la începutul anului 2007. Procuratura nu a putut acuza persoana din interior pentru încălcarea PIPA. El este acuzat doar că a furat un hard disk în valoare de 200 de dolari.
Nu este apreciat. Hacker din Zaporojie împotriva unei bănci ucrainene
adnotare
Un fost administrator de sistem al uneia dintre marile bănci din Ucraina a transferat aproximativ 5 milioane de grivne prin intermediul băncii în care anterior lucra din contul vămii regionale în contul unei inexistente companie falimentară din Dnepropetrovsk.
Descrierea incidentului
Cariera sa de administrator de sistem a început după ce a absolvit școala tehnică și a fost angajat de una dintre marile bănci din Ucraina în departamentul de software și hardware. După ceva timp, conducerea i-a observat talentul și a decis că va fi mai util băncii ca șef de departament. Cu toate acestea, apariția unui nou management la bancă a presupus și schimbări de personal. I s-a cerut să-și părăsească temporar postul. Curând, noua conducere a început să-și formeze echipa, dar talentul lui s-a dovedit a fi nerevendicat și i s-a oferit postul inexistent de șef adjunct, dar într-un alt departament. Ca urmare a unor astfel de schimbări de personal, a început să facă ceva complet diferit de ceea ce știa cel mai bine.
Administratorul de sistem nu a putut suporta această atitudine de conducere față de sine și și-a dat demisia din proprie voință. Cu toate acestea, era bântuit de propria mândrie și resentimente față de management, în plus, a vrut să demonstreze că este cel mai bun în afacerea lui și să se întoarcă la departamentul în care și-a început cariera.
După ce a demisionat, fostul administrator de sistem a decis să returneze interesul fostului management față de persoana sa, folosind imperfecțiunile sistemului „Bancă-Client” folosit în aproape toate băncile din Ucraina 2 . Planul administratorului de sistem era ca acesta să decidă să-și dezvolte propriul program de securitate și să-l ofere băncii, revenind la locul de muncă anterior. Implementarea planului a constat în pătrunderea sistemului Bancă-Client și efectuarea unor modificări minime la acesta. Întregul calcul a fost făcut pe baza faptului că banca ar fi descoperit un hack de sistem.
Pentru a pătrunde în sistemul specificat, fostul administrator de sistem a folosit parole și coduri pe care le-a învățat în timp ce lucra cu acest sistem. Toate celelalte informații necesare pentru hacking au fost obținute de pe diverse site-uri de hackeri, unde au fost descrise în detaliu diferite cazuri de hacking în rețele de computere, tehnici de hacking și tot software-ul necesar pentru hacking.
După ce a creat o breșă în sistem, fostul administrator de sistem a pătruns periodic în sistemul informatic al băncii și a lăsat diverse semne în acesta, încercând să atragă atenția asupra faptelor de hacking. Specialiștii băncii trebuiau să detecteze hack-ul și să tragă alarma, dar, spre surprinderea lui, nimeni nu a observat nici măcar pătrunderea în sistem.
Apoi administratorul de sistem a decis să-și schimbe planul, făcându-i ajustări care nu puteau trece neobservate. A decis să falsifice un ordin de plată și să îl folosească pentru a transfera o sumă mare prin sistemul informatic al băncii. Folosind un laptop și un telefon mobil cu modem încorporat, administratorul de sistem a pătruns în sistemul informatic al băncii de aproximativ 30 de ori: a căutat prin documente, conturi clienți, fluxuri de numerar - în căutarea clienților potriviți. A ales ca atare clienți vama regională și o companie falimentară din Dnepropetrovsk.
După ce a obținut din nou acces la sistemul băncii, a creat un ordin de plată prin care a retras 5 milioane de grivne din contul personal al vămii regionale și a transferat prin bancă în contul companiei falimentare. În plus, a făcut intenționat mai multe greșeli în „plată”, care, la rândul lor, ar fi trebuit să ajute și mai mult să atragă atenția specialiștilor bănci. Cu toate acestea, nici măcar astfel de fapte nu au fost observate de specialiștii băncii care deservesc sistemul Bank-Client și au transferat cu calm 5 milioane de grivne în contul unei companii defuncte.
În realitate, administratorul de sistem se aștepta ca fondurile să nu fie transferate, să se descopere faptul hacking-ului înainte ca fondurile să fie transferate, dar în practică totul a ieșit altfel și a devenit infractor, iar transferul său fals a escaladat în furt.
Faptul de hacking și furt de fonduri la scară deosebit de mare a fost descoperit la doar câteva ore de la transfer, când angajații băncii au sunat la vamă pentru a confirma transferul. Dar au raportat că nimeni nu a transferat o asemenea sumă. Banii au fost returnați de urgență băncii, iar un dosar penal a fost deschis la parchetul din regiunea Zaporojie.
Consecințe
Banca nu a suferit nicio pierdere, din moment ce banii au fost restituiți proprietarului, iar sistemul informatic a primit daune minime, în urma cărora conducerea băncii a refuzat orice pretenție împotriva fostului administrator de sistem.
În 2004, prin decretul președintelui Ucrainei, a fost întărită răspunderea penală pentru infracțiunile informatice: amenzi de la 600 la 1000 de minime scutite de taxe, închisoare de la 3 la 6 ani. Cu toate acestea, fostul administrator de sistem a comis o infracțiune înainte de intrarea în vigoare a decretului prezidențial.
La începutul anului 2005 a avut loc un proces al administratorului de sistem. El a fost acuzat de săvârșirea unei infracțiuni în temeiul părții 2 a articolului 361 din Codul penal al Ucrainei - interferență ilegală în funcționarea sistemelor informatice care dăunează și în temeiul părții 5 a articolului 185 - furt comis la scară deosebit de mare. Dar, deoarece conducerea băncii a refuzat să facă vreo pretenție împotriva lui, acuzația de furt a fost înlăturată de la el, iar partea 2 a articolului 361 a fost schimbată în partea 1 - interferență ilegală în funcționarea sistemelor informatice.
Tranzacționare necontrolată la banca Societe Generale
adnotare
Pe 24 ianuarie 2008, Societe Generale a anunțat o pierdere de 4,9 miliarde de euro din cauza mașinațiunilor comerciantului său Jerome Kerviel. După cum a arătat o investigație internă, de câțiva ani traderul a deschis poziții peste limită în futures pentru indici bursieri europeni. Valoarea totală a pozițiilor deschise s-a ridicat la 50 de miliarde de euro.
Descrierea incidentului
Din iulie 2006 până în septembrie 2007, sistemul de control intern al computerului a emis un avertisment cu privire la posibile încălcări de 75 de ori (de câte ori Jerome Kerviel a efectuat tranzacții neautorizate sau pozițiile sale au depășit limita admisă). Angajații departamentului de monitorizare a riscurilor băncii nu au efectuat verificări detaliate asupra acestor avertismente.
Kerviel a început să experimenteze tranzacțiile neautorizate în 2005. Apoi a luat o poziție scurtă pe acțiunile Allianz, așteptându-se ca piața să scadă. La scurt timp piata a scazut cu adevarat (dupa atentatele teroriste de la Londra), asa s-au castigat primii 500.000 de euro. Kerviel le-a povestit ulterior anchetatorilor despre sentimentele sale despre primul său succes: „Știam deja să-mi închid poziția și eram mândru de rezultat, dar în același timp am fost surprins. Succesul m-a făcut să continui, a fost ca un bulgăre de zăpadă... În iulie 2007, mi-am propus să iau o poziție scurtă în așteptarea unui declin al pieței, dar nu am primit sprijin de la managerul meu. Prognoza mea s-a adeverit și am făcut profit, de data aceasta a fost complet legal. Ulterior, am continuat să efectuez astfel de operațiuni pe piață, fie cu acordul superiorilor mei, fie în lipsa obiecției sale explicite... Până la 31 decembrie 2007, profitul meu a ajuns la 1,4 miliarde de euro. În acel moment, nu știam cum să declar asta la banca mea, deoarece era o sumă foarte mare care nu era declarată nicăieri. Eram fericit și mândru, dar nu am știut să explic conducerii mele primirea acestor bani și să nu am suspiciunea de a efectua tranzacții neautorizate. Prin urmare, am decis să-mi ascund profitul și să conduc operațiunea fictivă opusă...”
De fapt, la începutul lunii ianuarie a acelui an, Jerome Kerviel a reintrat în joc cu contracte futures pe cei trei indici Euro Stoxx 50, DAX și FTSE, care l-au ajutat să învingă piața la sfârșitul anului 2007 (deși a preferat să fie scurt la timp). Conform calculelor, în ajunul zilei de 11 ianuarie, portofoliul său conținea 707,9 mii futures (fiecare în valoare de 42,4 mii euro) pe Euro Stoxx 50, 93,3 mii futures (192,8 mii euro pe 1 bucată) pe DAX și 24,2 mii futures (82,7 mii euro). per 1 contract) pentru indicele FTSE. În total, poziţia speculativă a lui Kerviel era egală cu 50 de miliarde de euro, adică era mai mult decât valoarea băncii în care lucra.
Cunoscând momentul efectuării verificărilor, a deschis la momentul potrivit o poziție de acoperire fictivă, pe care a închis-o ulterior. Drept urmare, recenzenții nu au văzut niciodată o singură poziție care ar putea fi considerată riscantă. Ei nu au putut fi alarmați de cantitățile mari de tranzacții, care sunt destul de frecvente pe piața futures pe indici. A fost dezamăgit de tranzacțiile fictive efectuate din conturile clienților băncilor. Utilizarea conturilor diverșilor clienți ai băncilor nu a dus la probleme vizibile controlorilor. Cu toate acestea, de-a lungul timpului, Kerviel a început să folosească conturile acelorași clienți, ceea ce a dus la activitate „anormală” observată pe aceste conturi și, la rândul său, a atras atenția controlorilor. Acesta a fost sfârșitul înșelătoriei. S-a dovedit că partenerul lui Kerviel în afacerea de mai multe miliarde de dolari era o mare bancă germană, care ar fi confirmat prin e-mail tranzacția astronomică. Cu toate acestea, confirmarea electronică a stârnit suspiciuni în rândul inspectorilor, iar la Societe Generale a fost creată o comisie care să le verifice. Pe 19 ianuarie, ca răspuns la o solicitare, banca germană nu a recunoscut această tranzacție, după care comerciantul a acceptat să mărturisească.
Când a fost posibil să se afle dimensiunea astronomică a poziției speculative, CEO-ul și președintele consiliului de administrație al Societe Generale, Daniel Bouton, și-a anunțat intenția de a închide poziția riscantă deschisă de Kerviel. Acest lucru a durat două zile și a dus la pierderi de 4,9 miliarde de euro.
Oportunități din interior
Jerome Kerviel a lucrat cinci ani în așa-zisul back office al băncii, adică într-un departament care nu încheie direct nicio tranzacție. Se ocupă doar de contabilitate, executarea și înregistrarea tranzacțiilor și monitorizează comercianții. Această activitate ne-a permis să înțelegem caracteristicile sistemelor de control din bancă.
În 2005, Kerviel a fost promovat. A devenit un adevărat comerciant. Responsabilitățile imediate ale tânărului au inclus operațiuni de bază pentru a minimiza riscurile. Lucrând pe piața futures a indicilor bursieri europeni, Jerome Kerviel a trebuit să monitorizeze modul în care portofoliul de investiții al băncii se schimbă. Iar sarcina sa principală, după cum a explicat un reprezentant al Societe Generale, a fost să reducă riscurile jucând în direcția opusă: „În linii mari, văzând că banca pariază pe roșu, a trebuit să parieze pe negru”. La fel ca toți comercianții juniori, Kerviel avea o limită pe care nu o putea depăși, care a fost monitorizată de foștii săi colegi din back office. Societe Generale avea mai multe straturi de protecție, de exemplu comercianții puteau deschide poziții doar de pe computerul lor de lucru. Toate datele despre pozițiile de deschidere au fost transmise automat în timp real către back office. Dar, după cum se spune, cel mai bun braconier este un fost pădurar. Și banca a făcut o greșeală de neiertat punându-l pe fostul pădurar în postura de vânător. Jerome Kerviel, care avea aproape cinci ani de experiență în monitorizarea comercianților, nu i-a fost greu să ocolească acest sistem. Știa parolele altora, știa când aveau loc controalele la bancă și cunoștea bine tehnologia informației.
Cauze
Dacă Kerviel a fost implicat în fraudă, nu a fost în scopul îmbogățirii personale. Avocații săi spun asta, iar reprezentanții băncii recunosc și ei acest lucru, considerând acțiunile lui Kerviel iraționale. Kerviel însuși spune că a acționat exclusiv în interesul băncii și a vrut doar să-și demonstreze talentele de comerciant.
Consecințe
La sfârșitul anului 2007, activitățile sale au adus băncii un profit de aproximativ 2 miliarde de euro. În orice caz, asta spune însuși Kerviel, susținând că conducerea băncii probabil știa ce face, dar a preferat să închidă ochii atâta timp cât era profitabil.
Închiderea poziției riscante deschise de Kerviel a dus la pierderi de 4,9 miliarde de euro.
În mai 2008, Daniel Bouton a părăsit postul de CEO al Societe Generale și a fost înlocuit în această funcție de Frédéric Oudea. Un an mai târziu, a fost nevoit să demisioneze din funcția de președinte al consiliului de administrație al băncii. Motivul plecării sale a fost critica acerbă din partea presei: Bouton a fost acuzat de faptul că managerii de vârf ai băncii aflate sub controlul său au încurajat tranzacțiile financiare riscante efectuate de angajații băncii.
În ciuda sprijinului consiliului de administrație, presiunea asupra domnului Bouton a crescut. Acţionarii băncii şi mulţi politicieni francezi i-au cerut demisia. De asemenea, președintele francez Nicolas Sarkozy i-a cerut lui Daniel Bouton să demisioneze după ce s-a știut că în anul și jumătate dinaintea scandalului, sistemul informatic de control intern al Societății Generale a emis un avertisment de 75 de ori, adică de fiecare dată când Jerome Kerviel a efectuat tranzacții neautorizate posibile încălcări. .
Imediat după ce au fost descoperite pierderile, Societe Generale a creat o comisie specială pentru a investiga acțiunile comerciantului, care includea membri independenți ai consiliului de administrație al băncii și auditorii PricewaterhouseCoopers. Comisia a concluzionat că sistemul de control intern al băncii nu a fost suficient de eficient. Acest lucru a dus la imposibilitatea băncii de a preveni o asemenea fraudă la scară largă. Raportul precizează că „personalul băncii nu a efectuat verificări sistematice” ale activităților comerciantului, iar banca însăși nu avea „un sistem de control care ar putea preveni frauda”.
Raportul privind rezultatele auditului comerciantului arată că în urma rezultatelor investigației s-a luat decizia de „întărire semnificativă a procedurii de supraveghere internă a activităților angajaților Societe Generale”. Acest lucru se va realiza printr-o organizare mai strictă a activității diferitelor divizii ale băncii și coordonarea interacțiunii acestora. De asemenea, vor fi luate măsuri pentru urmărirea și personalizarea operațiunilor de tranzacționare ale angajaților băncii prin „consolidarea sistemului de securitate informatică și dezvoltarea de soluții de înaltă tehnologie pentru identificarea personală (biometrie)”.
Din cartea Asigurarea securității informațiilor în afaceri autorul Andrianov V.V.4.2.2. Tipologia incidentelor Generalizarea practicii mondiale ne permite să identificăm următoarele tipuri de incidente de securitate a informațiilor care implică personalul organizației: - dezvăluirea informațiilor oficiale; - falsificarea rapoartelor; - furtul de bunuri financiare și materiale; - sabotaj.
Din cartea Pensie: procedura de calcul si inregistrare autor Minaeva Lyubov Nikolaevna4.3.8. Investigarea incidentelor Un incident în care este implicat un angajat al unei organizații este o urgență pentru majoritatea organizațiilor. Prin urmare, modul în care este organizată o investigație depinde în mare măsură de cultura corporativă existentă a organizației. Dar poți cu încredere
Din cartea Day Trading in the Forex Market. Strategii de profit de Lyn Ketty2.5. Exemple Să luăm în considerare câteva opțiuni de atribuire a pensiilor de muncă în cazul transferului documentelor către organele teritoriale ale Fondului de pensii prin poștă: Exemplul 1 O cerere de atribuire a unei pensii de muncă pentru limită de vârstă a fost transmisă organului teritorial al fondului
Din cartea Practica managementului resurselor umane autor Armstrong Michael3.5. Exemple Exemplul 1 Experiența de muncă constă în perioade de muncă de la 15 martie 1966 până la 23 mai 1967; de la 15.09.1970 la 21.05.1987; de la 01.01.1989 la 31.12.1989; de la 04.09.1991 la 14.07.1996; de la 15.07.1996 la 12.07.1998 și serviciul militar de la 27.05.1967 la 09.06.1969 Să calculăm vechimea în muncă pentru a evalua drepturile de pensie
Din cartea autorului4.4. Exemple Exemplul 1 Inginerul Sergeev A.P., născut în 1950, a solicitat o pensie pentru limită de vârstă în martie 2010. În 2010, a împlinit 60 de ani. Vechimea totală pentru evaluarea drepturilor de pensie de la 1 ianuarie 2002 este de 32 de ani, 5 luni, 18 zile, inclusiv 30 de ani înainte de 1991.
Din cartea autorului6.3. Exemple Exemplu 1 Director de vânzări V.N. Sokolov a lucrat în baza unui contract de muncă de la 1 ianuarie 2010. La 1 ianuarie 2013, moare la vârsta de 25 de ani. În același timp, mai are părinți apți de muncă, o soție aptă de muncă și o fiică în vârstă de 3 ani. În acest caz, dreptul de a primi muncă
Din cartea autorului7.4. Exemple Exemplul 1 Manager Vasiliev R. S., 60 de ani. Vechimea totală conform carnetului de muncă pentru evaluarea drepturilor de pensie de la 1 ianuarie 2002 este de 40 de ani. Câștigul mediu lunar pentru 2000–2001, conform datelor contabile personalizate, este de 4.000 de ruble. Vom calcula și compara sumele pensiei conform
Din cartea autorului8.3. Exemple Exemplul 1 Un pensionar primește o pensie de invaliditate din grupa I. Din 20 mai până în 5 iunie 2009, a fost supus încă o reexaminare la BMSE și a fost recunoscut ca grupa III de dizabilități la 3 iunie 2009. Grupa de dizabilități în acest caz a scăzut. Partea de bază a pensiei este supusă
Din cartea autorului10.4. Exemple Exemplul 1 Decesul unui pensionar s-a produs la data de 28 ianuarie 2009. Vaduva pensionarului a solicitat pensie in februarie 2009. Nu s-a stabilit convietuirea vaduvei cu pensionarul in ziua decesului.In acest caz de pensie, organul teritorial al fondul acceptat
Din cartea autorului14.7. Exemple Exemplul 1 Koshkina V.N., care era dependentă de soțul ei decedat, a împlinit vârsta de 55 de ani la 3 luni după moartea acestuia. Am solicitat pensie dupa 1 an de la data decesului sotului meu.Conform legislatiei pensiilor pensia se va atribui de la data
Din cartea autorului17.5. Exemple Exemplul 1 Un antreprenor individual angajează patru persoane în baza unui contract de muncă: Moroz K.V. (n. 1978), Svetlova T. G. (n. 1968), Leonova T. N. (n. 1956) și Komarov S. N. (n. 1952). Să presupunem că salariul lunar al fiecăruia dintre ei este de 7.000 de ruble.
Din cartea autoruluiExemple Să ne uităm la câteva exemple despre cum funcționează această strategie: 1. Graficul de 15 minute a EUR/USD din Fig. 8.8. Conform regulilor acestei strategii, vedem că EUR/USD a scăzut și se tranzacționa sub media mobilă pe 20 de zile. Prețurile au continuat să scadă, îndreptându-se spre 1.2800, adică
Din cartea autoruluiExemple Să studiem câteva exemple.1. În fig. Figura 8.22 prezintă un grafic de 15 minute de USD/CAD. Raza totală a canalului este de aproximativ 30 de puncte. În conformitate cu strategia noastră, plasăm ordine de intrare cu 10 puncte deasupra și sub canal, adică la 1.2395 și 1.2349. Ordin de cumpărare executat
Din cartea autoruluiExemple Să ne uităm la câteva exemple ale acestei strategii în acţiune.1. În fig. Figura 8.25 prezintă graficul zilnic EUR/USD. Pe 27 octombrie 2004, mediile mobile EUR/USD au format o ordine corectă consistentă. Deschidem o poziție la cinci lumânări după începerea formării la 1.2820.
Salutare tuturor Habrazhitelnik,
Foarte des, ca serviciu de proces, auziți o întrebare foarte populară din partea angajaților departamentelor IT mari și mici: care este diferența dintre o solicitare de serviciu și un incident?
Discuțiile pe această temă sunt la fel de vechi ca toate metodologiile de management IT luate împreună, totuși, să ne întoarcem la sursele primare.
Ce ne spune ITIL (traducerea oficială a glosarului conform celei de-a treia versiuni):
Solicitare de service- o solicitare a utilizatorului de informare, sau consultare, sau o modificare standard, acces la un serviciu IT.
Incident- întreruperea neplanificată a unui serviciu IT sau reducerea calității unui serviciu IT.
Ca de obicei, metodologia nu pătrunde în profunzimea lucrurilor și chiar nu-i place să răspundă la întrebările de fond ale angajaților oricărui Service Desk care clasifică solicitările utilizatorilor. Între timp, există o mulțime de astfel de întrebări, iată câteva exemple:
1) Apel Christomatic de la un utilizator care cere resetarea parolei - cum să-l clasific ca solicitare de serviciu sau incident? Sau poate ca un incident de securitate a informațiilor?
2) Un apel de la un utilizator al cărui e-mail corporativ nu funcționează. O analiză rapidă a cererii sugerează că utilizatorul trebuie să efectueze configurarea inițială a clientului de e-mail. Cu toate acestea, din punctul lui de vedere, acesta este un incident, pentru că... serviciul nu este disponibil și nimeni nu l-a notificat că „e-mailul în sine nu va zbura”
Inutil să spunem că clasificarea primară este foarte importantă, deoarece determină întregul ciclu de viață ulterior al recursului, inclusiv. și termenele limită.
Înțelegerea mea despre această problemă se rezumă la o chestiune de evaluare întreruperi ale serviciului pentru consumatorul final și astfel:
Incident- aceasta este, în cele mai multe cazuri, o întrerupere sau o întrerupere parțială a unui serviciu IT care a fost furnizat anterior utilizatorului într-un mod aprobat (serviciul este disponibil 24/7 sau 5/8).
Exemplu: Contabilul-șef al companiei a pierdut brusc accesul la sistemul de raportare financiară. Pe de o parte, asigurarea accesului este o cerere clasică de serviciu, dar în acest caz există o întrerupere clară a serviciului și, în consecință, o degradare parțială a procesului de afaceri.
Solicitare de service- acesta este un apel al unui utilizator care este interesat să conecteze un serviciu suplimentar sau să îmbunătățească funcționalitatea serviciilor existente.
Exemplu: Un utilizator deosebit de curios a încercat să deschidă unul dintre modulele aceluiași sistem de raportare financiară, dar a primit un mesaj de eroare. Din punctul lui de vedere acesta este o întâmplare, întrucât nu și-a atins scopul dorit și nu a primit informațiile pe care le căuta, ci, din punct de vedere. descrisă mai sus este o cerere clasică de serviciu pentru acces care necesită aprobare și este efectuată conform unei proceduri standard într-un interval de timp convenit.
În același timp, nu trebuie să uităm de varietatea de cazuri speciale care sunt în general dificil de clasificat; punctul de vedere descris mai sus nu se pretinde a fi o dogmă, ci se străduiește doar să contribuie la minimizarea numărului de solicitări clasificate incorect și să îmbunătățească timpul general de răspuns IT la nevoile afacerii.